Mar 11th, 2008
Yes, I know I didn’t update this blog lately, but my father is in ICU since December 20th with a severe acute pancreatitis. After 82 days and 5 surgeries, it seems he is recovering well, although his situation is still critical according to doctors. It has been a hard couple of months, very busy and stressful, so I didn’t have much time to update this blog nor to respond some comments. Sorry, I’ll do it in the next few weeks.
Anyway, as a distraction, I changed the blog theme (as you may have noticed) with a major makeover, since I was getting bored with the old one. Hopefully you’ll like this one, I believe it is more readable now. And if you find any error, don’t hesitate to contact me.
Tomorrow, I’ll be leaving for London to attend the QCon 2008 conference. So stay tuned, as I plan to live blog and twitter the event (as last year). If you are the same conference and would like to meet me, please come in and say hi!.
Ferdy, so sorry to hear about your father’s illness. 🙁
Feb 18th, 2008
Over the course of my career working as a software engineer, I have had the opportunity to play with different data structures (arrays, vectors, trees, …) and different persistence data systems, from hierarchical databases (IMS DB) to indexed and relative files (VSAM) to RDBMS. Even so, I consider myself as an apprentice, and I still have the insane curiosity to learn new persistence data models. That’s the reason why, recently, I have been playing with CouchDb.
For those of you who do not know CouchDb, it is a distributed, fast, reliable, fault-tolerant and schema-free document-oriented database accessible via a RESTful JSON API. It has been getting a lot of attention lately, specially after Amazon launched its cloud database system, SimpleDB, which has some similarities with CouchDb, and after IBM hired its creator, Damien Katz, that caused the donation and acceptance of CouchDb as an incubation project by the Apache Software Foundation. Despite this hype, it is still an alpha level software, it’s stable enough for testing but not ready for a production environment.
The first interesting feature about CouchDb is that, unlike typical relational systems, it will not enforce you to use an schema. Instead of designing tables, CouchDb stores in a flat file, called database, documents, which are lists of key-value pairs, called fields, with no predefined structure. If you want to think in a relational way, databases are tables, documents are rows, and fields are columns, but in the same database (table), you could have different documents (rows) and each row could have any number of different fields (columns) without the need to structure their data types (field = dynamic key + value). So you don’t need to structure your data in advance, you can do it later if you want using views, which will organize your data adding structure back to semi-structured data. It’s a “Data First vs. Structure First” strategy.
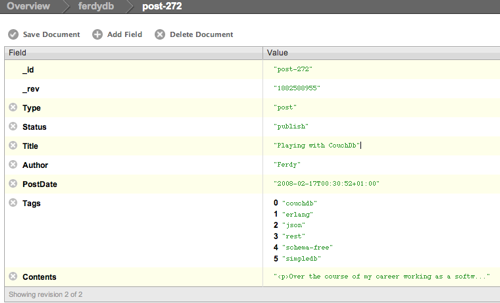
Here it is an example of a document (using the built in web front end):
This lack of schema, however, is not a suite-for-all solution, but it could be advantageous in some situations. I’ll give you a simple example. Imagine you need to create a repository of information related to all the software components of your information system (something like a CMDB), that is programs (or classes), databases, configuration files, web pages, … Components has common attributes and specific attributes depending on the type of product. For example, common attributes are type of product, name, description, … and specific attributes for a program are language, technology used (DB2, MQSeries, …) … You will have several approaches to store these information:
- Design a relational table for each type of product with all the attributes (common and specific);
- Use only one table with all the common attributes plus some generic attributes (for example, attrib1 varchar(255), …), and an external data dictionary that identifies and describes the format of each generic atribute;
- No predefined structure, each row stores different attributes depending on the type of product.
From a pure relational perspective, it seems natural to use the first option. But what happens if you’re a tools vendor and you let the users add they own products? You still have the choice to use the first option, but the problem is a bit more complicated, as you’ll have to deal with some unknown tables (and, perhaps, not normalized). OK, no problema here, we’ll just use the second alternative. It’s a perfect choice (in fact, I’ve used this approach occasionally), but doesn’t seem very natural to the relational discipline. And here is when it comes the third approach, each row will have different columns (as a key+value pair) representing the product attributes. In summary, all three options are correct (and yes, I’m polite because I don’t want a flame war now), but in this case, it’s more advantageous to use the schema-free approach.
Another interesting feature is that CouchDb uses the Erlang OTP platform (internally, you’ll never see it), which is a perfect choice for highly concurrent access and fault-tolerant systems. But being highly concurrent means that you must try to avoid locks, something hard to design if you want to enforce all ACID properties. To deal with this situation, CouchDb uses a MVCC and a lockless optimistic writer mechanism (in comparison to Mnesia, Erlang’s DBMS, which uses a pessimistic locking). Using these approaches, readers could access documents without being locked by a writer, seeing only the version of the document that existed when he began reading (despite a writer updated the document at the meantime), because data is always versioned by the writers. But this strategy involves big database files, because they are growing all the time (remember, writers never overwrites data, they only append it, even if you’re deleting data). And even though CouchDb has an automatically compaction process that clones all the data without any service interruption, it would be nice to see some performance metrics to check which will be the performance parsing large files in Erlang.
The last interesting feature is its simple REST API to manage the data, using JSON for data transport. It is very easy to create, read, update or delete documents and views, that have a unique URI, using HTTP resources. Yes, and that means no painful database drivers, just regular HTTP connections, so you can use your favourite HTTP library. Let’s see some examples using cURL:
Getting a list of all databases on my local CouchDb server:
curl -i http://localhost:5984/_all_dbs
And the response:
HTTP/1.1 200 OK
Server: inets/develop
Date: Sat, 16 Feb 2008 23:57:32 GMT
Cache-Control: no-cache
Pragma: no-cache
Expires: Sat, 16 Feb 2008 23:57:32 GMT
Transfer-Encoding: chunked
Content-Type: text/plain;charset=utf-8
["ferdydb","test_suite_db","test_suite_db_a","test_suite_db_b"]
Retrieving a document:
curl -i http://localhost:5984/ferdydb/post-272/
And the response. Remember that documents are simple JSON objects:
HTTP/1.1 200 OK
Server: inets/develop
Date: Sat, 16 Feb 2008 23:58:25 GMT
Cache-Control: no-cache
Pragma: no-cache
Expires: Sat, 16 Feb 2008 23:58:25 GMT
Transfer-Encoding: chunked
Content-Type: text/plain;charset=utf-8
Etag: 1882588955
{
"_id":"post-272",
"_rev":"1882588955",
"Type":"post",
"Status":"publish",
"Title":"Playing with CouchDb",
"Author":"Ferdy",
"PostDate":"2008-02-17T00:30:52+01:00",
"Tags":["couchdb","erlang","json","rest","schema-free","simpledb"],
"Contents":"<p>Over the course of my career working as a softw..."
}
Did you see the Etag header? Let’s see if it works:
curl -i http://localhost:5984/ferdydb/post-272/ \
-H "If-None-Match: "1882588955""
It works! Here is the response:
HTTP/1.1 304 Not Modified
Server: inets/develop
Content-Type: text/html
Date: Sun, 17 Feb 2008 00:26:26 GMT
Cache-Control: no-cache
Pragma: no-cache
Expires: Sun, 17 Feb 2008 00:26:26 GMT
Etag: 1882588955
Enough experiments for today, right?
After reading this brief summary, and if you come from a relational model discipline, your first reaction may be “WTF“. But I would encourage you to go deeper with this new persistence data model approach checking the technical overview page at the CouchDb Documentation Wiki or reading these slides by Jan Lehnardt (don’t forget the comments also). You’ll find a lot more features that I didn’t explain in this post. And of course, share with me your opinion!
Nice article! Very informative and helpful as I learn CouchDB. Thanks.
-Reuben :)+<